
읽는 시간: 3분
크리에이티브 최적화 방식 찾기



iOS 앱 퍼포먼스 마케팅에서 가장 큰 장애물은 무엇일까요?
후보자가 꽤 많지만 Apple의 개인정보보호용 임계치가 유력합니다.
개인정보보호용 임계치(privacy threshold)란? Apple이 앱 마케터가 앱 사용자 개인을 식별하거나 추정도 하지 못하도록 설정한 장치입니다.
어떤 원리일까요? Apple은 SKAdNetwork 포스트백으로 발송되는 전환 값을 통제합니다. 유의미한 전환 값을 받으려면 한 마케팅 캠페인으로 발생한 앱 인스톨 수가 일정 수준을 넘겨야 합니다. 임계치를 충족시키지 않으면 SKAN 포스트백에서 전환 값은 “null”로 전송됩니다. 임계치를 충족하면 전환 값은 숫자로 발송됩니다.

이러한 제약은 개인정보보호 측면에서 중요하지만, 마케터는 앱 설치 후 어떤 이벤트가 발생했는지, 매체 별 성과가 어떻게 다른지를 파악할 수 없습니다. 전환 값이 없으면 앱 설치 데이터만 남는데, 앱 설치 데이터는 앱 설치 후 발생하는 인앱 이벤트 데이터보다 중요도가 떨어집니다.
Apple이 정확한 임계치를 공개하지 않아서 안타깝게도 앱 기업들은 추측만 계속 할 뿐입니다.
전환 값이 없으면 앱 설치 후에 발생하는 유저 활동이나 발생하는 수익에 대해 알 수 없습니다. 이렇게 전환 값이 누락되면 eCPA와 ROAS가 잘못 계산되어 최적화와 예산 책정을 잘못할 위험이 있습니다.
예를 들어보겠습니다.
A 매체는 B 매체보다 고가치 유저를 더 많이 유입시킵니다. A 매체로 유입된 유저는 앱을 더 오래 사용하며 인앱 구매도 더 많이 해, 충성 유저가 될 가능성이 높습니다.
그러나 A 매체는 일일 앱 설치 수가 적기 때문에 Apple의 개인정보보호용 임계치에 미달되곤 합니다. 그 결과, A 매체의 성과를 알리는 포스트백 내 전환 값은 가려져서 전달됩니다.
반면, B 매체의 일일 앱 설치 수는 개인정보보호용 임계치를 충족시킬만큼 커서 전환 값 데이터가 그대로 전송됩니다.
전환 값 데이터만들 두고 보면, B 매체 트래픽의 가치는 보통 이하이지만, A 매체처럼 데이터가 아예 없는 것보다는 낫습니다. 그런데 단지 전환 값이 보인다는 이유만으로 B 매체가 A 매체보다 성능이 좋은 것처럼 보입니다. 마케터는 이러한 결과를 보고 성과가 더 좋은 매체에서 예산을 끌어와 성과가 낮은 매체에 쏟아붓고 맙니다. 마케터를 탓할 수 있을까요? 이것이 마케팅 성과의 극히 일부를 나타내는 데이터만 가지고 마케팅을 최적화할 때 생기는 허점입니다.
개인정보보호용 임계치로 매체 평균 11%의 데이터 공백이 발생합니다. 더 큰 문제는 따로 있습니다. 개인정보보호용 임계치는 마케터에게 어떤 채널의 성과가 더 좋은지를 알려준다는 SKAN의 목적을 무마시킵니다. 보이는 데이터가 엉뚱한 방향으로 이끌 수 있는데 어떻게 올바른 선택을 할 수 있을까요?
2021년 4월 iOS 14.5와 함께 ATT(AppTrackingTransparency)가 시행되었을 때, 무효화된 전환 값은 매체 평균 전체 전환 값의 약 8% 였습니다. 2021년 5월, 그리고 Apple이 개인정보보호용 임계치 알고리즘을 변경한 2021년 10월에 무효처리된 전환 값 비율이 급격히 증가했습니다. 전환 값이 없는 비율은 고점을 찍은 뒤 빠르게 내려갔고 다시 안정되었습니다.
이후 광고주의 노력에 상관없이 무효 전환 값 비율은 평균 약 11%로 안정화되었으며 Apple의 알고리즘 변경으로 인해 때때로 급증했습니다.
2021년 10월 최고치인 45%보다는 낫지만 데이터 유실율 11%는 여전히 상당히 큽니다. 이렇게 데이터 공백이 크면 마케팅 방향성을 잡기 어렵습니다.
저희 엔지니어 팀은 몇 달 동안 Apple의 개인정보보호형 임계치에 대해 집중적으로 연구했습니다. 우선 SKAN 메커니즘을 연구하고 이를 토대로 무효화된 전환 값을 유의미한 정보로 전환하려고 했습니다.
SKAN 연구 결과, 저희는 컨버전 값 마스킹 여부는 앱 설치 이후 앱 사용 활동과 상관없이 앱 설치 중에 결정된다는 점을 깨달았습니다. 즉, Apple은 앱 설치 시점에 개인정보보호용 임계치에 도달했는지 판단합니다.
전환 값(앱 사용 활동 정보)이 없는 유저가 전환 값이 있는 유저와 동일한 방식으로 행동한다고 가정하면, 행동 분포 패턴도 비슷할 것입니다. 예를 들어보겠습니다.
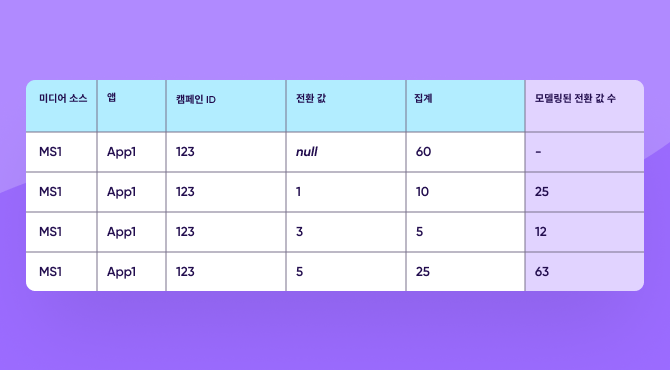
한 앱 기업이 캠페인을 실행하여 앱 설치가 100건 발생했으며 그 중 60건이 개인정보보호용 임계치 미달로 전환 값이 가려졌습니다. (앱 설치가 최소 61건 이상이 되어야 전환 값을 볼 수 있다고 가정하겠습니다.)
나머지 40건은 전환 값 1, 3, 5를 반환했습니다.
이 전환 값 1, 3, 5의 분포율이 전체 앱 설치 100건을 나타낸다고 가정합니다.
이 예시에서는 유의미한 전환 값이 있는 인스톨 40건 중 10건의 전환 값은 1입니다. 40건 중 10건은 전체의 25%입니다. 그렇다면 실제 인스톨 100건 중 25%에 해당하는 25건의 전환 값이 1이 되지 않을까요?
저희가 처음에 고안한 이 로직은 순진할정도로 단순했습니다. 구현하기 쉽고 어느 정도 타당하지만 큰 단점이 두 가지 있었습니다.
이 단순한 로직은 실제 문제를 시원하게 해결할 수 없을 뿐더러 치명적인 단점이 있어 별로 쓸모가 없었습니다.
이러한 단점을 해결하기 위해, 저희는 한층 진화한 머신 러닝 모델을 개발했습니다. 이 모델은 광고 세트 단위까지 광고 성과(전환 값)를 정확도 높게 계산할 수 있으며 광고 세트나 캠페인으로 발생한 인스톨 수가 적어도 측정이 가능합니다.
이 모델링은 ‘계층적 베이지안 분석(Hierarchical Bayesian Analysis)’에 기반합니다. 인스톨 한 건 한 건, 낱개의 데이터가 아니라 (광고 세트, 캠페인 등의 단위로) 집약된 형태의 데이터에서 전환 값의 분포도를 측정하기 위해 충분한 데이터가 있는지 확인하는 통계 실험을 합니다. 데이터가 충분하지 않으면 같은 계층이나 더 상위 계층의 분포 상태를 적용합니다.
대표적인 데이터셋에 대해 학습시키고 학습에 사용된 동일 데이터셋의 부분 집합에 근거하여 모델의 정확성을 검증합니다. 그리고 별개의 데이터셋을 사용하여 학습된 모델의 분포도 일반화 기능을 테스트 합니다.
복잡한 개념이지만 핵심은 저희가 이 모델을 광범위하게 테스트하여 정확성을 확인했다는 것입니다. 이 모델에 대한 검증은 다음과 같이 진행했습니다. 마스킹되지 않은 전환 값 데이터셋을 테스트 데이터셋으로 준비하고 이 데이터셋의 전환 값을 직접 마스킹한 다음, 이 모델이 숨겨진 전환 값을 계산하도록 했습니다. 그리고 머신 러닝으로 모델링된 전환 값과 삭제한 실제 전환 값을 비교하고 그 차이를 계산했습니다.
모델의 정확도는 88%였습니다. 누락된 전환 값의 88%를 예측했습니다. 테스트 할때마다 정확도가 일관되게 꾸준히 유지되었고, 오늘 드디어 이 모델을 공개합니다.
이 모델의 장점은 Apple의 개인정보보호 가이드라인을 지키면서 마케터의 골칫거리를 해결한다는 점입니다. 개인 정보가 드러나는 유저 레벨 데이터는 노출되지 않도록 하고 마케팅에 필요한 집약형 데이터만 제공합니다.
누락된 데이터를 정확도 높은 데이터 모델링으로 보완하는 기술의 효과는 분명합니다. 그런데 이 모델링 기술의 또다른 효과가 있습니다. 앱스플라이어의 Single Source of Truth(SSOT) 솔루션으로 이제 SKAN 포스트백에 전환 값이 없을지라도 인스톨과 인앱 이벤트 중복 삭제가 가능합니다. 전환 값 모델링 기술은 iOS 캠페인 최적화에 걸림돌이 되는 데이터 중복 집계 이슈도 해결합니다.
베타에 참여한 앱스플라이어 고객사들은 주요 지표의 정확도가 향상되었음을 확인했습니다. 모델링된 수익 데이터(ROAS)를 모델링되지 않은 수익 데이터와 비교했을 때 평균 15% 향상되었습니다.
저희는 개인정보와 데이터 정확성을 모두 지킬 수 있는 방향으로 의미있는 솔루션을 계속해서 개발해 나가겠습니다. SKAdNetwork에 추가되는 기능에 맞춰 데이터 모델을 업데이트하여 더욱 정확한 머신 러닝 기술과 집약형 데이터를 제공하도록 최선을 다하겠습니다.

